Keras框架
Keras 是一个用 Python 编写的高级神经网络 API,它能够以 TensorFlow, CNTK, 或者 Theano 作为后端运行。Keras 的开发重点是支持快速的实验。能够以最小的时延把你的想法转换为实验结果,是做好研究的关键。
由于本项目基于快速成型的模型搭建原则,所以应用Keras这种高层API更加方便。
允许简单而快速的原型设计(由于用户友好,高度模块化,可扩展性)。 同时支持卷积神经网络和循环神经网络,以及两者的组合。 在 CPU 和 GPU 上无缝运行。
Keras的特征
用户友好。 Keras 是为人类而不是为机器设计的 API。它把用户体验放在首要和中心位置。Keras 遵循减少认知困难的最佳实践:它提供一致且简单的 API,将常见用例所需的用户操作数量降至最低,并且在用户错误时提供清晰和可操作的反馈。
模块化。 模型被理解为由独立的、完全可配置的模块构成的序列或图。这些模块可以以尽可能少的限制组装在一起。特别是神经网络层、损失函数、优化器、初始化方法、激活函数、正则化方法,它们都是可以结合起来构建新模型的模块。
易扩展性。 新的模块是很容易添加的(作为新的类和函数),现有的模块已经提供了充足的示例。由于能够轻松地创建可以提高表现力的新模块,Keras 更加适合高级研究。
基于 Python 实现。 Keras 没有特定格式的单独配置文件。模型定义在 Python 代码中,这些代码紧凑,易于调试,并且易于扩展。
使用LSTM网络生成股价数据
LSTM模型对于时间序列数据的训练来说,具备先天的优势。在本项目中,我借鉴了大神的模型:https://github.com/jaungiers/LSTM-Neural-Network-for-Time-Series-Prediction
模型的预测结果如下:
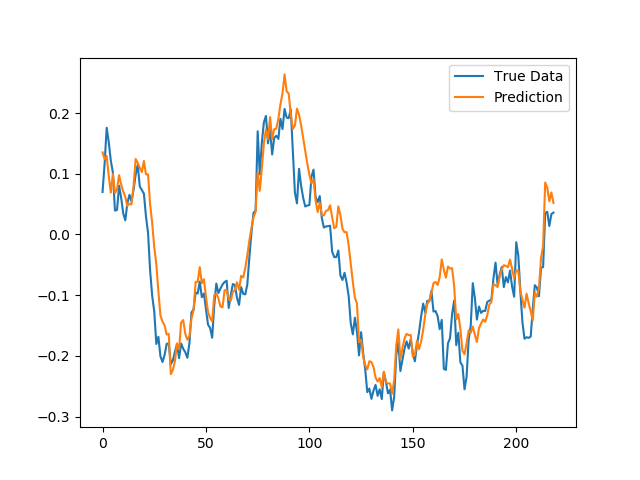
上图是对股价逐个点进行预测,虽然看上去与实际价格吻合的很好,但是这个结果具有一定的欺骗性,因为模型只需要预测一个点,那么,在下一次预测中,这个预测点实际上就被真实数据取代了,那么模型只需要给出实际误差不是很大的结果就可以莫混过关。
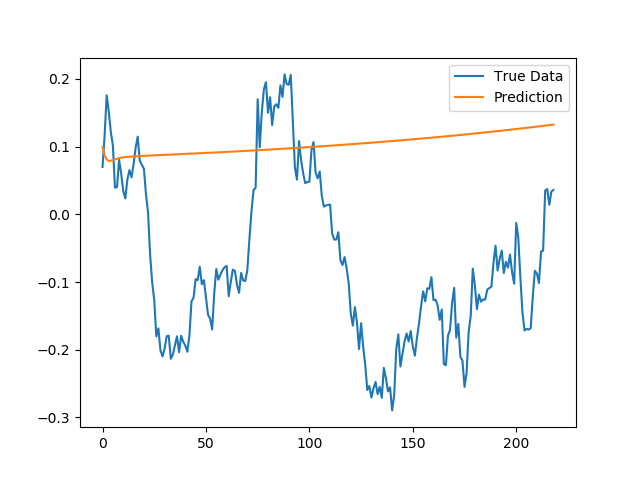
上图是对整个测试序列进行预测,这个结果明显看出,模型并没有学到什么,对于股价波动没有丝毫的敏感性。
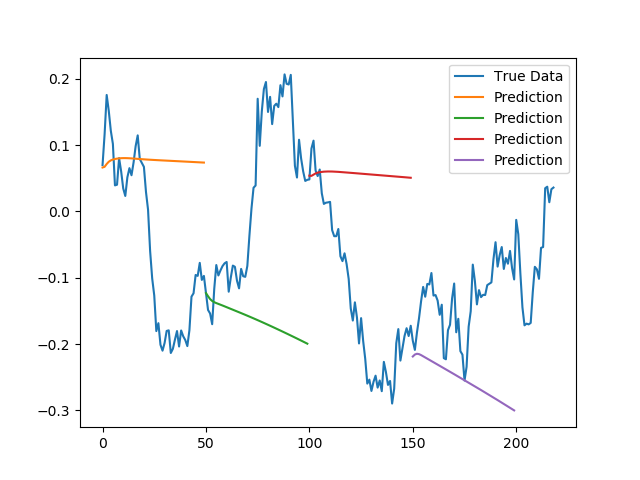
上图是以序列为单位进行预测,可以看出虽然在序列的开始节点是比较准确的,但是模型依然对波动不敏感,而且每个序列的第一个点的预测结果跟上面逐个点预测的原因是一样的,再继续使用模型预测波动趋势就会发现模型并没有对股价的涨跌做出反应,这说明模型学习的效果并不理想。
项目使用的是三层叠加的LSTM网络,每层网络100维,最后使用一个全连接层对股价预测输出结果。
我仔细研究了模型思路,发现了一些可以改进的地方:
1.原来的项目中只是仅仅使用了股价的收盘价和成交量为训练数据,只有二维,这显然无法表达股价波动的多种影响因素。我使用了Tushare中获取的股价数据,进行特征整合和去重、特征工程之后,得到了488维的股价数据,也就是说,每一日的股价,伴随有488个不同层面的特征数据对其进行描述。我认为,只有当我们获得了全部数据,才能够真正的发现数据背后的规律。
2.模型使用叠加的LSTM网络可以很好的发现序列数据中的深层结构,但是网络应该将这个序列的结构信息也传递给全连接层,这样才能真正的捕捉时间序列信息,但是原模型并没有将序列整个输出,而仅仅将最后一个 LSTM cell的hidden state输出给全连接层,这样会造成模型学习的知识丢失。
3.由于LSTM网络传递的是三维的数据,在我的实验数据中,数据维度是(2364,50,488),也就是有2364个样本,每个样本有488个特征,以50个时间步为一个训练数据进行训练。这样网络最后输出的结果也是三维的,所以我在Dense层之前添加了一个Flatten层,用来展平三维数据到二维,然后增加了一个Dropout层避免过拟合,这样再输出到Dense层之后,全连接的网络会学习到整个序列在时间上的结构信息,更加有利于准确预测结果。
综上,我修改了原项目中的模型结构和数据结构,主要是增加了新的网络层,并对数据维度进行了扩展,我使用了2008年到2018年十年的股价日收盘价数据进行训练,模型参数总量为169万,预测结果有了很大的提升。
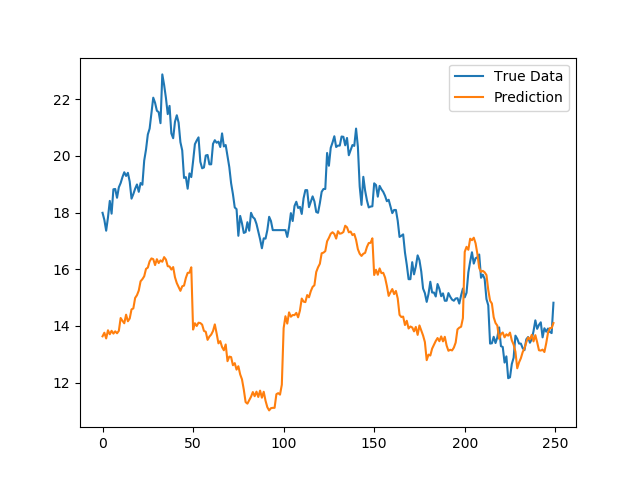
我们可以看到,虽然在股价的绝对值上,预测结果有较大的偏差,但是股价的走势以及每日走势细节。尤其是对股价的剧烈波动都基本能够准确捕捉,可以说模型已经基本学习到了股价波动的趋势。
相比于原模型来说,在以序列为单位进行预测这项任务上,新的模型更能学习到股价趋势。
这个模型只是我实现模型的第一个版本,但是基本可以证明我的思路是正确的,这个版本有一个明显的问题:
我对预测数据的切分,仅仅是按照序列长度进行了等分,相当于模型只是对结果进行了int(test_len/seq_len)个预测,这样的预测很容易受到噪声影响。
所以我又对预测结果进行了改进,借鉴了滑动窗口的思路,将预测结果和滑动窗口结合,对同一个点的结果进行平均,消除噪声的影响。
然后,得到的结果,有那么一点萌 (—.—)
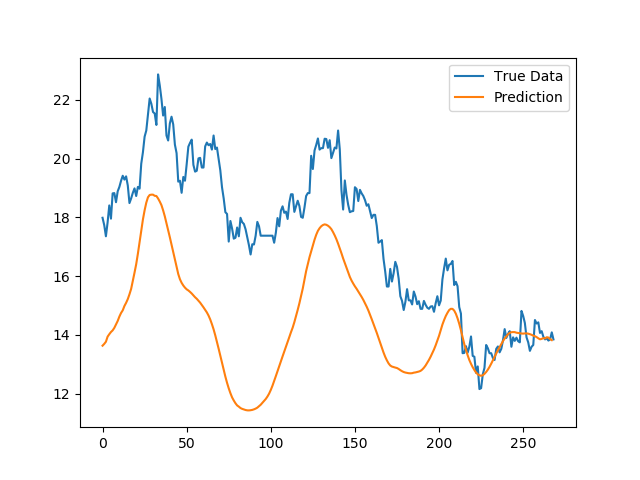
看来时间窗口平滑真的很平滑。
但是不得不说,股价的趋势仍然可以很好的预测出来。如果以这样的预测结果进行量化交易,可以通过对预测值求导的方式,估算出涨跌趋势,从而指导交易。
另外,对于这个模型,还有一个改进的方法。
之前对于训练数据和测试数据,都是在时间窗口内进行的标准化。标准化会对数据的进行重新分布,将数据集的均值和方差都设为标准正态分布。那么问题来了,训练集和测试集实际上每个样本数据都是基于不同的均值和方差的,但是标准化之后它们就具有相同的均值和方差。这样会损失一些信息。如果我们在训练之前,将整个训练集和测试集统一进行一次标准化,使得整体的均值方差保持一致,这样,基于时间的均值和方差序列信息就会更好的保留,并且可能会在一定程度上提高预测的精确度。以上,感觉表述不清,我们用实验来验证一下。
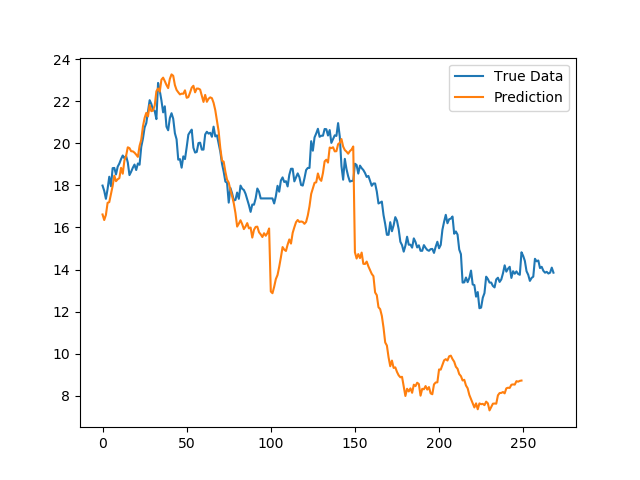
上图是全局标准化之后的结果,我们可以看到,在绝对值上面,相对于窗口标准化的预测结果,股价更加接近于真实数据。在这里我发现应该是窗口预测的原因,两个窗口衔接的位置容易出现比较大的误差。这在实际当中是不可能出现的。于是我又有了一个对窗口衔接处做修正的方案:
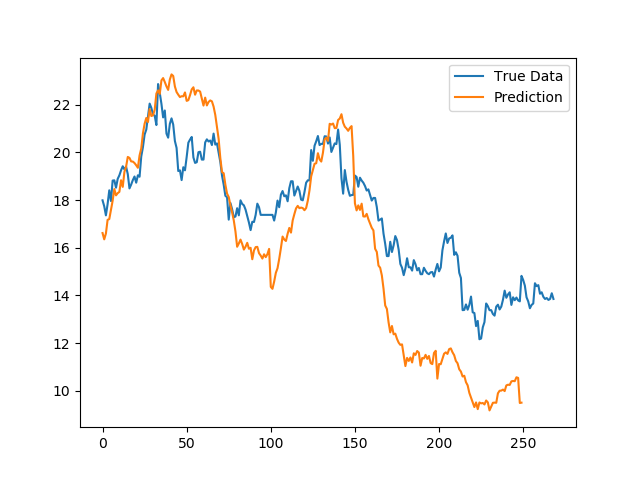
上图对窗口的衔接处做了处理,如果前一个窗口的最后一个数据和下一个窗口的第一个数据之间的偏差超过了涨跌停板的限制时,我们人为的将后面一个窗口的数据都修正到涨跌停板的范围内,这样,既不会影响在窗口内模型预测的结果,也使得结果数据更加自然、真实。
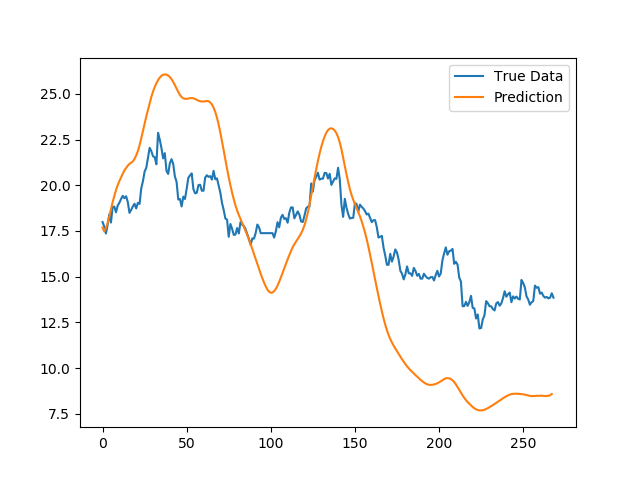
上面是全局标准化之后的滑动平均之后的结果,发现也是可以捕获基本的趋势,但是在股价绝对值上面,差别较大。
以上,是基于LSTM网络时间序列预测模型对股价数据的预测情况。基本上,学术和金融界对个这个模型的研究到这里就差不多了。但是我仍然在思考一个问题:
股价预测模型更多的是需要通过历史数据预测未来走势,这并不是简单的时间序列监督学习问题,更多的是将历史数据作为未来股价的特征,并对模型进行训练。虽然LSTM网络就可以捕捉历史信息,但是实际训练时,我们是将每个时间点数据拼接起来作为时间序列,并将这个序列输入模型,预测时,我们也是通过测试集的特征,预测股价这个结果。如果在实际应用中,我并不知道未来一段时间的特征,那我就无法预测未来的股价,我们的模型实际上就没有做到预知未来。
所以,我在思考,有没有可能将未来股价作为标签,现在的数据作为特征,直接在训练数据上就体现出“用过去预测未来”这种理念呢?
带着这个问题,我需要重新规划我的数据集。数据集中,训练集和测试集应该这样划分:
1.过去的数据特征应该可以映射到未来的股价上,即投资者们可能在投资策略和布局上有自己一套计划,这个计划可能短到几天,长到几年,如果我们能够将过去的特征与未来的股价波动构建联系,那么就是说我们发现了众多投资者的策略的规律,这样可以很好的预测未来股价。
2.这种划分还需要避免以下问题,那就是不能够人为的定义训练时间窗口。因为我们的模型的理想状态是通过训练自己发现股票投资者的投资策略和股价的波动的历史原因,而不是我们定义一个时间窗口,单纯以时间窗口的数据进行训练模型。
想破了脑袋,也想不出如何规划这样的训练数据:必须以全部时间步的训练数据为特征,并且标签为未来的未知数据。这样的训练模型,恐怕不是监督学习能搞定的。
综上,我感到监督学习已经无能为力。这是由监督学习的框架和理念决定的,它无法产生新的数据,只能在原有数据上不断近似和逼近。
但是通过使用LSTM模型对高维特征进行分析,我们仍然可以看到,模型能够学习到一些价格波动规律,这就说明股价在一定程度上是可预测的!我们需要综合各种深度学习模型并应用到实际需求当中。监督模型可以挖掘特定的时间序列中特征集合与标签之间的内在联系,无监督模型可以自己去发现样本集的特征、分布等高维的规律,并用编码或者神经网络去表征。我们既需要发现在一段时间内股价与特征之间的关系,也需要发现股价的历史信息中的分布信息等高维信息,并以此为依据去预测未来的股价波动。这是监督模型和非监督模型的结合。
之前,我使用了LSTM模型,以50个交易日为一个period作为训练样本,训练了能够捕捉股价波动趋势的模型,取得了想要的效果。但是模型最大的问题是:
1.股价预测任务不是监督学习任务,我们在无法获得未来股价的特征时,显然也就无法预测未来股价。
2.股价的波动趋势能够被模型学习到,主要原因可能是开盘价、最高最低价等与收盘价强相关的信息作为特征,模型可以比较容易的推测出结果,模型就不需要学习上市公司财报、财务数据等基本面数据或者成交量等技术指标,所以,这个模型可能没有学习到股价的真正特征。
针对以上问题,我也是想破了脑袋叫破了喉咙。决定以四步走的形式,彻底解决这个问题:
1.重新规划训练模型。这一次,我想让模型学习到历史数据对未来股价的影响,也就是说,我能够在只知道现在和历史的成交信息的基础上,预测出未来n-m个交易日的股价。在训练数据上,以n为窗口,1为步长划分数据,在n这个窗口内,取m=λn,λ一般取0.9,也就是说将窗口内m个数据特征作为训练数据,而n-m个标签作为这个窗口训练的标签,这样的话,模型就可以训练出m天的数据对未来n-m股价的映射。仍然通过LSTM网络进行训练和测试。
2.如果步骤1可以得到比较满意的效果,那么说明模型可以学到历史数据对未来股价的影响情况,那么,我们就可以构建一个序列生成模型GAN,以LSTM为生成器,CNN为判别器,同时还对股价特征空间进行编码。
3.在这个基础上,我们再利用Bert模型对市场信息、上市公司财报等数据进行编码和情感分析,可以得到一个关于市场积极程度的编码向量,利用这个编码向量对GAN模型生成向量进行加权,就可以将市场短期的情绪加入到模型生成中,从而训练出既能够把握市场长期趋势,又能够考虑到短期的财经新闻和消息对股价影响的模型。
4.最后,对于多重的模型,我们既要交替训练,又要使用强化学习不同模型loss的权重进行探索和调试,期待最后收敛到一个合理的范围。
以上,就是我目前对于整个系统的全部思路,可以说是一边学习,一边实验,一边调整思路,好在一开始的夙愿和想法的大方向,都没有变,只是在细节和实现路径上,不断的试错和修正。
那么接下来,任何开源的项目都没有做过的模型,就要开始搭建了。
1.本想从数据的组织上解决预测的问题,经过试验后发现自己太天真了。
模型:三层堆叠LSTM,latent_dim=256,return_seq=True,Dropout=0.4 数据:”sequence_length”: 100, “train_test_split”: 0.9, “predict_window”: 0.1,
按照之前的计划,我使用100天的数据作为一个数据窗口,将整个数据集先进行标准化,再进行窗口划分,再按照train_test_split=0.9比例分为训练集和测试集,窗口内,根据predict_window=0.1,将前90个489维的数据作为训练数据,后面10个收盘价作为标签,进行训练,预测时,将预测结果进行拼接,得到股价预测走势图。
Epoch 1/5 2092/2092 [==============================] - 47s 23ms/step - loss: 27.6827 - val_loss: 3.0706
Epoch 2/5 2092/2092 [==============================] - 45s 21ms/step - loss: 2.6332 - val_loss: 2.8802
Epoch 3/5 2092/2092 [==============================] - 45s 22ms/step - loss: 1.7592 - val_loss: 2.7003
Epoch 4/5 2092/2092 [==============================] - 58s 28ms/step - loss: 1.5383 - val_loss: 3.2447
训练情况还可以,训练误差和验证误差都可控,最后由于val_loss升高而earlystop了,但是最后的预测结果出现了很大问题。 上图。
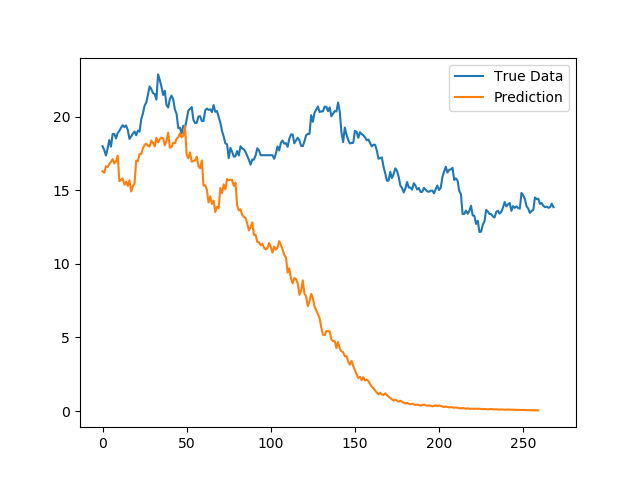
我们可以看到,股价预测结果在一开始还基本捕捉到了走势,但是随着时间的增加,后面的预测结果出现很大的偏差。基本可以说,时间序列预测任务,模型的参数是在不断变化的。里面提到的概念漂移问题在这次实验中体现的很明显。 参考这篇文章,https://zhuanlan.zhihu.com/p/54413813
所谓概念漂移,表示目标变量的统计特性随着时间的推移以不可预见的方式变化的现象,也就是每过一段时间序列的规律是会变化的。所以,在这种情况下,拿全部时间内的数据去训练,就相当于是增加了各种噪声,预测精度是会下降的。所以,一种解决办法是不断的取最新的一阶段内的数据来训练模型做预测。之前做过一个变压器油温预测的数据,实验了用全量数据,一年内的数据,半年,3个月,一个月的数据做训练,其后几天的数据做预测,发现一个月的效果是最好的。那么如果你要问我,怎么判断一个序列是否存在概念漂移,我会告诉你,我也不知道,做实验吧!
本次实验中,由于股价模型的参数不断变化,预测结果在一开始还能基本符合真实数据,随着时间推移逐渐出现了偏差积累的情况。
咋办?
然后我又调整了超参数,将数据窗口拉长,预测窗口压缩,得到的结果…..
数据:”sequence_length”: 200, “train_test_split”: 0.95, “predict_window”: 0.05,
结果嘛,模型直接炸了,验证集误差爆炸了,这说明,增加窗口长度没有任何帮助。那就再减小它。
数据:”sequence_length”: 50, “train_test_split”: 0.9, “predict_window”: 0.1,
结果呢?
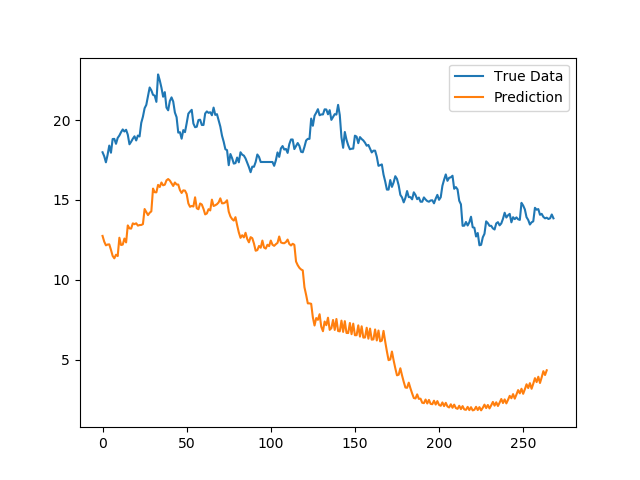
我们发现模型普遍在后面的预测结果上出现问题,而一开始的预测结果虽然绝对值偏差较大,但是趋势基本吻合。
这就更加印证了我的判断,股市模型参数是随着时间变化的,无法用一个静态模型预测未来长期的走势,模型必须也要随着时间变化。
这样的话,股价预测这种时间序列预测问题,过于久远的数据其实对未来的预测并没有太大的作用,或者这样理解,对于日线数据预测,有效的预测应该是基于最近n天的数据,而对于月线或者年线预测,有效的可能就是最近n月、n年,这个时间窗口内才对未来的预测有贡献,而历史数据的贡献程度,取决于我们要怎样预测未来,是按照日线收盘价预测还是年线收盘价预测,就是这样。
那么,我们的终极目标是想预测未来几天的股价走势,通过实验证明:一是根据日线数据来进行趋势预测,具体的股价绝对值,我们还需要利用其他数据进行修正。
我们知道,长期股价预测看基本面数据,以上实验就是实现了这个预测,但是结果并不理想,我们转而想要预测短期股价波动。这里,我们计划使用成熟的Bert服务,对财经新闻进行编码并训练,看看财经新闻对股价波动是什么样的影响。